How to implement edge computing in 5 steps
In order to get edge computing implementation right, IT administrators must first figure out how intelligent their IoT edge devices need to be and how best to group those devices.

Edge computing is almost a necessity when it comes to creating a workable IoT architecture. Edge computing manages a complex environment where IoT devices could swamp an uncontrolled platform with unwanted data and where monitoring events and managing responses become impossible.
What problems does edge computing address?
Edge computing, based around the use of dedicated server-based systems that capture, aggregate and analyze data from IoT devices, can lead to a far more effective and efficient IoT environment that doesn't negatively affect the overall business IT platform.
The cloud platform itself consists of a virtualized mix of compute, storage and network elements that can flex to meet the resource demands of the workloads placed upon it. However, the IoT devices -- different types of devices indicated by different colors in Figure 1 below -- are essentially outside of the cloud, being far more physical items. These then need to be aggregated behind physical edge servers that capture and carry out analysis and even initiate some events. The edge servers, if necessary, send data to the cloud for more extensive analysis and can receive demands from the cloud for the provision of data as required. Therefore, the data created by the IoT devices is separated to a large extent from the main data loads on the cloud. The edge servers create air-gapped environments where only important data gets to the main data network.
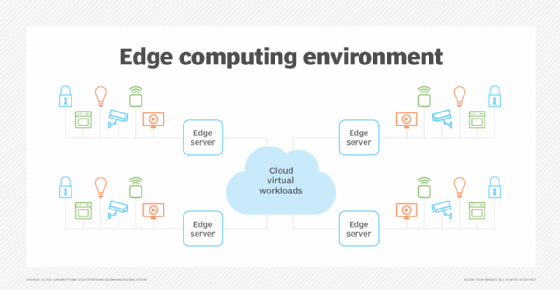
It isn't the easiest thing to get right, though; there must be careful planning to get the most out of it. Edge computing isn't just a case of slapping a few extra devices onto a platform and leaving everything to get on with it. A lot of pre-planning and thought is needed to ensure that the IoT/edge computing environment works as desired. Indeed, where cloud computing is involved, the complexities of dealing with a mix of physical and virtual environments, as well as the possibility of a hybrid mix of owned and third-party systems, means that edge computing must be right from the start.
Key steps to implement edge computing
Here are the main steps that must be taken to get edge computing right.
1. Decide how much intelligence there will be in your IoT devices.
The more intelligence per device, the less intelligence is needed in the edge servers themselves. This is due to data already being filtered at the source: the IoT device. Intelligent, standardized IoT devices will provide lower volumes of data in more easily managed formats. However, intelligent IoT devices have an associated higher cost; it's important to find a happy medium.
Bear in mind that adding a few dollars to each IoT device to gain small amounts of additional intelligence can lead to an aggregate cost of thousands of dollars, which might be better spent on intelligent edge computing systems.
2. Decide how you are going to group your IoT devices.
This might be decided to some extent by how you deal with step one -- a disparate grouping of intelligent IoT devices might be easier to manage than one of a collection of relatively dumb devices, as less filtering, analysis and reporting will have to be done on the data streams.
Don't group all similar IoT devices on a network through an edge device. This will still result in massive data transfers across the network. The idea is to group devices creating data into manageable areas and capture the data as close to the group as possible to minimize cross-platform data traffic.
Therefore, it might be preferable to group devices by proximity, rather than capability. Proximity grouping also lowers latency and enables far faster response to identified events. Again, this means that the edge server must be more intelligent, as it will deal with different data streams reporting on different events.
3. Define carefully what the preferable outcomes are.
It's tempting to try to use edge systems to completely carve out areas of a platform and to use these servers to fully manage the IoT devices, but you shouldn't. A monitored high reading in one IoT device through one edge server might be meaningless on its own, for example, yet when compared to similar devices being monitored through all edge servers, it might be incredibly important. As such, it's necessary to define what a true exception is and how such exceptions must be handled.
Maintain a good rules engine, and update it as required to reflect how priorities and needs are changing. And make sure that a full and real-time inventory of the environment is in place to ensure that the edge servers are operating against the real environment -- not something that was in place some time ago.
4. Use a hub-and-spoke approach.
To manage the flow of data that's required, you must have an edge infrastructure that consists of different edge servers placed across a network with a hierarchical manner of dealing with the data between them. The optimum way to deal with such a complex system is to have the lowest-cost, least-intelligent edge servers -- a relative use of terminology, these systems might be quite intelligent and costly in themselves -- as close to the IoT devices as possible.
Where these edge servers identify events that might be of further interest, they must be able to send the relevant data to a more intelligent, more central server that is managing a group of or all the edge servers. This central system can then apply more intelligence to data analysis and better decide what actions are required. It's also necessary for the edge servers to work in a bilateral manner: The outer edge servers must be able to identify events and send data to the center, while the center also must be able to demand data in real time from the outer edge servers to bolster the data it's dealing with.
An example here could be in a data center where one edge server picks up a high temperature reading. As far as it's concerned, it's a local event, but it sends that event through to the central server. That server requests that all other outer edge servers send through readings from all appropriate temperature monitors. If they are all within limits, then yes, it's a local problem, probably due to a single item overheating. However, if other reports come through of even minor increases in temperature, it might mean that the cooling system for the whole data center has failed -- requiring a much different set of events to correct.
Where proximity grouping lowers direct data latency for all IoT devices under the control of the one edge server, a hub-and-spoke model lowers the time needed for analyzing data as the central server only needs to deal with known, high-priority data.
5. Employ advanced data analytics and reporting.
Although automation has come a long way, it's still not 100% accurate. As such, there will be cases -- there could be quite a lot of them due to the lack of maturity of the area currently -- where edge servers must alert a human to an action to be taken. False positives and negatives must be avoided and possible routes to remediation must be shown to any human that gets involved. As such, don't scrimp on the analytics tools used, and make sure that reporting is carried out in a clear and meaningful manner.
Considerations for an edge computing implementation
Edge computing is likely to become as necessary to an organization's overall platform as cloud is. It's not going to be a case of "either/or" but rather "where does edge fit best within the overall architecture?" For many organizations, it will be in managing the growth of IoT, whether this is for production lines, control systems, intelligent building management or whatever else. For others, it might be in more highly specialized use cases, such as dealing with highly "chatty" data systems that sit badly on standard cloud platforms. However, edge computing should be an area that organizations are looking into now. Leaving it for a future time could result in major changes being required to existing cloud architectures and more time and money spent on trying to overlay and integrate more physical systems into a highly virtualized environment.
Edge computing is still in its early days, and it is easy to get things wrong by not applying the right amount of forethought upfront. These points should help in ensuring that the right edge deployment strategy is put in place.







