Edge computing vs. cloud computing: What's the difference?
IT administrators don't need to choose between the edge and cloud, but they need to know the pros and cons of each technology to best incorporate them in business operations.

Many organizations use cloud as a part of their overall IT platform. The flexibility of resource management and the promise of higher overall utilization rates can equate to cost savings.
In addition, the public cloud is an attractive platform for many because of the skills saved through a third party managing the underlying platform, the massive scale of such platforms and the capability for data to be held securely around the globe.
However, organizations have run into issues with centralized data collection and analysis. This has led to a rise in edge computing as an alternative.
What is cloud computing?
With cloud computing, a platform is created where resources -- compute, storage and network -- can be flexibly applied to a specific workload in a highly virtualized manner to better meet the needs of modern dynamic workloads. That platform runs many workloads and allows resource sharing across them, often using business-driven priorities to define which workload gets first dibs on any resources.
Advantages of cloud computing
The cloud has many advantages, including the following:
- Highly dynamic flexible resource provisioning. With the right configuration, cloud can flex the resources applied to a workload on demand. For example, a workload that has a sudden spike in its need for compute power can have this applied from virtual resource heaps. When the spike is over, the resource can be freed up and placed back in the heap, ready to be provisioned to meet another workload's requirements.
- Highly virtualized. In a well-architected cloud, the virtualization of the platform means workloads gain high levels of portability. An instance of an app can be moved from one part of the cloud to another, if required, and this can be done rapidly. This improves availability and performance and helps avoid issues such as distributed denial-of-service attacks.
Disadvantages of cloud computing
The cloud also has its disadvantages, including the following:
- There still remains a resource ceiling. This is true, particularly in private clouds. Utilization rates of physical servers often climb no higher than the low tens of percentages -- running in the single percentages for large periods of time. A private cloud might drive overall utilization rates up to the mid tens of percentages but could hit issues around network constraints. The costs associated with such poor resource utilization not only include the power requirements to keep everything running, but also the cooling required, OS and app licensing, and maintenance. Public clouds are likely already managing hundreds of thousands of workloads and running in the high tens of percentages for resource utilization, but they can better handle the headroom required; private clouds only managing tens to hundreds of workloads might not have such capabilities.
- There are difficulties in dealing with more physical aspects of an environment. Even with virtualization, there's an unbreakable link between virtual and physical worlds. Although public clouds have internal high-speed network connects and highly optimized connections between their own data centers, such high-speed interconnects aren't generally in place between an organization and the public cloud. If centralized data analysis in the public cloud is dependent on a slow, lower bandwidth connection to access data from an organization's environment, when data loads are high, major issues such as data sawtoothing and packet collisions could occur.
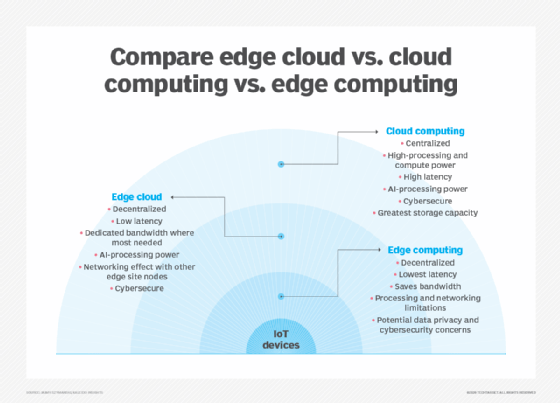
What is edge computing?
With edge computing, the idea is to work with the centralized nature of the cloud but avoid the transfer and analysis of data where it isn't necessary. Moving intelligence closer to where the data is created and where intelligent decisions are required can improve overall performance.
Edge computing can be carried out either via a special computing unit, known as an edge device, or via a specialized software image that runs on a standard physical or virtual server co-located close to the devices creating the data. Edge computing services can then be used to capture, manipulate and analyze the data and make decisions on what actions should be carried out in what areas.
Advantages of edge computing
Edge computing includes the following advantages:
- Edge computing places data intelligence closer to where it's needed. This means responses are improved. For areas such as production line systems or smart buildings, this more immediate data handling and decision-making can be a necessity.
- It minimizes data transfers across the broader network. Those parts of the overall platform where network traffic might cause issues can be left available for data that must be centralized.
- It enables a more "onion skin" approach to data transfers to be enacted. Here, the edge device can capture and analyze the data coming in from a group of different devices and can filter out the obviously useless data. It can also see if there is anything that points to an immediate issue and send that data for more detailed analysis to the centralized cloud or to another more capable edge device closer to the core.
Disadvantages of edge computing
Edge computing also suffers from issues, including the following:
- Defining the edge can be difficult. Cloud platforms have already muddied the definition of where the edge of an IT platform and its constituent parts lie. With modern edge computing, the need to define a "virtual edge" consisting of a collection of closely co-located data generating devices is a core architectural need. However, taking IoT as an example, just how many IoT devices should one edge device be responsible for? What different types of IoT devices should a single edge device be responsible for, even when they are all closely co-located?
- False positives and negatives can occur. With the majority of IoT devices on the market today being relatively dumb devices, the edge device must take over responsibility for data collection and analysis. However, edge devices must be cost-effective; an edge device that looks after 10 IoT devices can't cost thousands of dollars. Finding the edge device or compute instance that provides the right amount of intelligence for the right amount of money remains a problem that IT teams must be careful to balance.
Does edge computing replace cloud computing?
No, it definitely does not. The cloud provides an underlying platform that increases an organization's overall flexibility while offering opportunities to lower costs and improve responsiveness to market changes. Edge computing provides a means of adding extra performance improvements, particularly around data analysis and decision-making. The trick is to implement a well-blended mix of an underlying cloud platform combined with the judicious use of edge computing to meet the organization's needs.
Cloud in a modern IT environment
One of the main issues that cloud must address is the burgeoning growth of IoT. Here, devices are dotted around an organization's physical IT environment, carrying out a range of different tasks from simple measurements to complex actions against the requirements of a production line or smart building, for example. IoT devices are data-rich, but incredibly "noisy," meaning much of that data is of little to no use. This data also tends to be chatty -- it isn't a continuous stream but created over time as a series of events. Such data doesn't need to traverse the network, but many IoT devices don't have the built-in intelligence to know this.
Herein lies the dichotomy: Trying to fully manage an IoT environment through a cloud-only platform isn't the optimal way of doing things. The problem is that for the cloud to deal with all the data created by these IoT devices, all the data must traverse the network to where that cloud capability resides. This leads to latency in the data itself, along with what can be a major hit on the overall bandwidth of the cloud, even with its resource flexibility. Edge computing optimizes data management and minimizes unneeded data network traffic.
How to choose between edge and cloud
The choice here is where the edge should be used in an overall hybrid cloud platform. Where large data workloads make sense -- for example, when looking at buying patterns across online shoppers or analyzing full data sets -- using a central cloud platform makes sense. However, when looking at discrete groupings of similar devices where a lot of data is of little use or more immediacy in decision-making is required, using edge devices or services can help in aggregating, filtering and analyzing the data in a more optimized manner.
For the IT architect, ensuring the overall architecture meets the organization's needs is key. However, the introduction of edge services can be carried out in a piecemeal manner, replacing existing centralized services with edge as priorities demand.
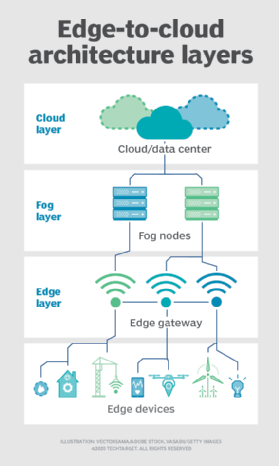
Fog computing and edge cloud
Those looking into edge computing in a cloud world might also come across the term fog computing -- this essentially brings the two concepts together as more of a single concept. Edge computing devices are placed as close to the actual need as possible, but with close integration to the main centralized cloud platform.
Another term you might see is edge cloud, which means different things to different people; many see it as being the same as fog computing. For others, it's more of a fully integrated and optimized total infrastructure platform that relies on the underlying network constructs for managing data flows and analysis. However, fog computing and edge cloud are similar concepts.
For most organizations, the result is a fog computing/edge cloud environment. Blending the overall platform provides enhanced capabilities and flexibility for the future.






